
Attaques Meltdown & Spectre
Cet article est une explication technique abordable des attaques Meltdown et Spectre qui j’espère permettra à d’autres de mieux comprendre les mécanismes et la portée de ces attaques.
Les mécanismes en jeu
Ces deux attaques sont différentes de celles dont nous entendons parler majoritairement. Elles touchent le matériel, ou hardware, et non pas des applications. Pour comprendre ces attaques, il est nécessaire de faire un petit récapitulatif sur le fonctionnement et l’optimisation d’un processeur.
Fonctionnement d’un processeur
Un processeur, ce n’est rien d’autre qu’une calculatrice. Au début, des calculs étaient envoyés à un processeur, celui-ci effectuait les calculs qu’on lui envoyait dans l’ordre, les uns après les autres, puis il retournait les résultats.
Lorsqu’un programme est exécuté, les données à traiter sont dans la mémoire vive (qu’on appelle aussi simplemement mémoire), ou RAM. Pour traiter une instruction, les données nécessaires au traitement doivent être envoyées depuis la mémoire vive vers la mémoire interne du processeur pour qu’il les traite. Ensuite, le résultat est enregistré à nouveau en mémoire.
Si le temps de traitement des données par le processeur est environ le même que le temps de récupération des données en mémoire, tout ça se coordonne très bien. En effet, pendant que le processeur traite une instruction, les données de la prochaîne instruction sont rapatriées, permettant d’avoir un flux tendu.
Avec le temps, le matériel a évolué, et les processeurs sont devenus très, très rapides. Tellement rapides qu’ils ont largement devancé les accès en mémoire. Ainsi, aujourd’hui, le traitement d’une instruction se fait environ en 0.5 nano-seconde, tandis qu’un accès mémoire se fait en 20 nano-secondes.
Par conséquent, si jamais le processeur traitait les instructions linéairement, il passerait la plupart de son temps à attendre les données, au lieu de travailler.
C’est pourquoi les constructeurs se sont penchés sur le sujet afin d’optimiser le processus de traitement de leurs processeurs.
Pour entrer un peu plus dans les détails et comprendre les optimisations, il faut savoir qu’un processeur Intel se découpe en 3 parties :
- Le Front-end, qui récupère les instructions en mémoire, et qui les découpe en micro-instructions
- L’Execution Engine possède différentes unités d’exécution, Execution Units, qui ne sont rien d’autre que des petits centres de calculs, spécialisés pour différentes tâches
- Le Memory Subsystem permettant d’enregistrer en cache des données traitées par le processeur afin d’optimiser les futurs accès.
Voici une vision (simplifiée) de ces 3 parties
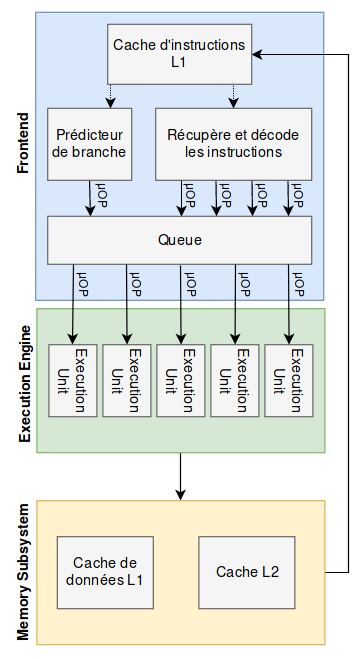
Avec ces précisions en tête, nous allons voir les 3 mécanismes d’optimisation qui entrent en jeu dans les deux attaques Meltdown et Spectre, en s’intéressant principalement au fonctionnement des processeurs Intel qui sont vulnérables pour les deux attaques.
Ces optimisations existent sur la plupart des processeurs récents. Certains cependant ne les mettent pas toutes en pratique.
Cache
Le premier mécanisme d’optimisation dont nous allons parler est le cache. L’idée étant qu’en principe, lorsqu’une zone mémoire est lue, il y a des grandes chances pour qu’elle soit lue à nouveau, ou qu’une zone mémoire adjacente soit lue rapidement après.
C’est très souvent le cas, que ce soit lors de la lecture d’un fichier, ou le parcours d’un tableau de données. La plupart du temps, la lecture se fait dans l’ordre, et les zones mémoires sont contigües.
Prenons l’exemple suivant qui illustre ce principe :
cache.c
#include <stdio.h>
#include <x86intrin.h>
int get_access_time(volatile char *addr)
{
/*
* Une variable volatile est une variable sur laquelle aucune optimisation de compilation n'est appliquée
* permettant de s'assurer que les instructions suivantes seront effectuées telles qu'écrites, sans
* optimisation (changement dans l'ordre des opérations, par exemple).
*/
int time1, time2, junk;
volatile int j;
time1 = __rdtscp(&junk);
j = *addr;
time2 = __rdtscp(&junk);
return time2 - time1;
}
int main(int c, char **v) {
char pixis[] = "hackndo";
// On flush le cache pour que la chaîne ne soit pas en cache
_mm_clflush(pixis);
//Premier accès, la chaîne n'est pas en cache
printf("Avant la mise en cache : %d\n", get_access_time(pixis));
/*
* Le processeur a accédé à la chaîne de caractères
* Ainsi, il a mis en cache la chaîne ainsi qu'un peu
* de mémoire avant et après.
*/
// Deuxième accès, après la mise en cache
printf("Après la mise en cache : %d\n", get_access_time(pixis));
return 0;
}
Une chaîne de caractères "hackndo" est enregistrée en mémoire vive. Nous vidons le cache par précaution, puis nous accédons une première fois à la chaîne. Elle est alors cherchée en mémoire vive, puis elle est mise en cache pour les prochains accès. Nous y accédons donc une deuxième fois. Voici le résultat de ce programme :
pixis@hackndo:~/spectre-meltdown $ make cache
cc cache.c -o cache
pixis@hackndo:~/spectre-meltdown $ ./cache
Avant la mise en cache : 1024
Après la mise en cache : 230
Les deux valeurs sont le nombre de cycles qui se sont passés au moment de l’accès à la variable. Nous voyons les bénéfices immenses du cache qui a divisé par presque 5 le temps d’accès !
Out-of-order
Comme nous l’avons expliqué, un processeur calcule très vite, tellement vite qu’il risque d’attendre beaucoup de temps s’il devait exécuter les instructions les unes à la suite des autres.
Pour pallier à ce problème, une deuxième optimisation a été pensée : les processeurs aujourd’hui exécutent des instructions en parallèle avec leurs différentes unités d’exécution, ou Execution Unit.
Prenons un exemple simplifié :
var_A = a + b
var_B = c + d
var_C = e + f
Dans ce cas, au lieu de faire 3 calculs les uns après les autres, avec 3 accès mémoire, le processeur peut calculer en même temps var_A, var_B et var_C dans l’ordre qu’il veut.
Ainsi, il peut optimiser ces 3 instructions en 1 instruction :
var_C, var_A, var_B = e + f, a + b, c + d # Calcul dans le désordre, ce qui n'a pas d'importance
Le processeur a ainsi optimisé ses ressources en faisant travailler 3 unités d’exécution en même temps pour effectuer 3 calculs indépendants, au lieu de les effectuer un par un en attendant les accès mémoire.
Il arrivera parfois que des instructions soient interdites, comme l’exemple suivant
var_A = a/0
var_B = c + d
var_C = e + f
De la même manière, les 3 instructions seront potentiellement exécutées dans le désordre
var_C, var_A, var_B = e + f, a/0, c + d
donc les variables var_B et var_C seront potentiellement calculées avant que le processeur se rende compte qu’il y a une erreur avec var_A.
Quand le processeur s’en rend compte, il va alors annuler les changements effectués par les instructions qui devaient suivre et qui ont été exécutées en parallèle. Cette annulation fait croire que les calculs de var_B et var_C n’ont jamais été faits. Ni vu, ni connu. À priori.
Prédiction
Toujours dans l’optique d’optimiser le temps de traitement, et donc pour éviter d’attendre les accès mémoire, le processeur va tenter de faire des choix par lui même lorsqu’il arrive à des conditions dans les instructions.
Si par exemple le code suivant est compilé
int i;
for (i=0; i<1000; i++)
{
/**
** Du code ...
**
**/
// Condition
if (i < 999)
{
// INSTRUCTIONS
}
/**
** Du code ...
**
**/
}
alors le processeur va se retrouver plusieurs fois devant une condition if. Il a alors le choix soit de continuer les instructions dans l’ordre (donc il ne prend pas la branche), soit de prendre le saut de la condition (prendre la branche).
La plupart du temps, la condition sera vraie donc les instructions INSTRUCTIONS seront effectuées. Le Branch Target Buffer (BTB) enregistre toutes les branches prises lors de conditions, et le processeur s’en sert pour essayer de deviner la bonne branche à choisir pour la prochaîne apparition de la condition.
Une fois qu’il a prédit la branche, le processeur va effectuer les instructions de cette branche avant même de savoir si sa branche est réellement la bonne branche. Bien sûr, le calcul de la condition va finir par se terminer. Si la branche était la bonne, alors les instructions continuent, et les changements effectués par les instructions exécutées en avance sont gardés.
En revanche, si la branche prédite n’était pas la bonne, alors les changements en mémoire sont annulés, et le processeur revient en arrière pour prendre la bonne branche.
Dans notre exemple, le processeur va prédire que la condition est vraie presque 1000 fois, et lorsque i sera égal à 999, il se trompera probablement mais il aura gagné tellement de temps pour les 999 autres fois que ce mécanisme est largement payant.
Les vulnérabilités
Avec les trois principes évoqués ci-dessus, les processeurs peuvent aller plus vite que les limites matérielles imposées. Cependant, la course à la rapidité a un prix.
Ces optimisations sont faites pour ne pas laisser de trace en mémoire RAM en cas de mauvaises prédictions, ou en cas d’erreur quand les instructions ne sont pas exécutées dans l’ordre. Seulement voilà, elles laissent tout de même des informations dans le cache.
Ainsi, dans le cas suivant les instructions peuvent être exécutées en parallèle, comme nous l’avons vu dans l’optimisation out-of-order
raise(Exception); // ERREUR
value = kernel_space[0x42];
junk = buffer[value]
Une erreur va être levée, mais les instructions suivantes vont tout de même être exécutées.
Si le buffer n’était pas dans le cache, mais que les deux instructions sont exécutées, alors la mémoire qui se trouve à l’index value du buffer va être mise en cache puisqu’il y a eu un accès à cette zone, et que le processeur met en cache les zones mémoire accédées pour que les accès futurs soient plus rapides.
Comme le processeur va ensuite voir qu’il y a eu une erreur, les assignations de value et de junk seront annulées, mais la mise en cache de la valeur à l’index value de buffer ne le sera pas. On a donc une trace qui est laissée.
C’est un exemple qui s’approche de l’attaque Meltdown, démontrant que ces optimisations laissent finalement des informations, et risquent alors de faire fuiter des données sensibles.
Nous avons le même type de trace dans le cache lorsqu’une prédiction de branche est fausse, et que les instructions qui ont été exécutées à tort écrivent dans le cache.
Nous allons alors voir dans les chapitres suivants les deux attaques qui exploitent ce problème.
Meltdown
La particularité de Meltdown est que cette attaque exploite une vulnérabilité sur certains processeurs. En effet, les instructions out-of-order peuvent accéder à la mémoire du noyau, alors que cela devrait être interdit. C’est donc en utilisant cette faille que l’attaque permet de récupérer les informations contenues dans l’espace d’adressage du noyau.
Ensuite, la difficulté concernant les attaques qui touchent à la microarchitecture (tout ce qui est matériel) est de sortir les informations qui ont fuité.
L’approche de l’attaque Meltdown se découpe en deux parties : L’exfiltration de la donnée secrète, puis la récupération de celle-ci.
Exfiltrer l’information de la mémoire réservée au noyau
La première permet de sortir l’information secrète du kernel.
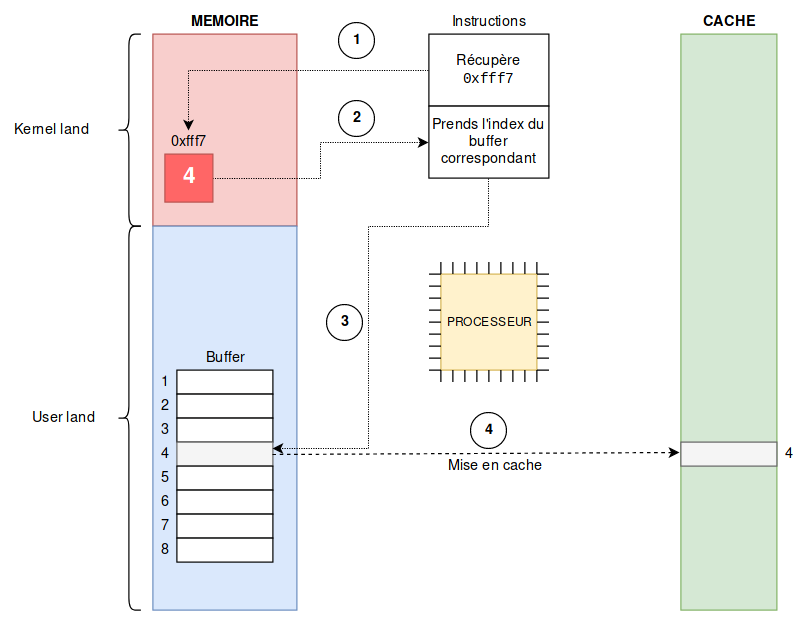
Un buffer est construit en amont, avec plusieurs sections qui, quand elle sont mises en cache, le sont indépendamment les unes des autres. Nous allons prendre dans l’exemple 8 sections.
L’idée est de trouver une valeur secrète dans le noyau entre 0 et 7, et d’accéder à l’index correspondant du buffer, pour que cet index soit mis en cache.
Dans notre exemple, pour récupérer une valeur entre 0 et 7, il faut récupérer 3 bits d’information (ce qui donne 8 possibilités 000, 001, 010, …, 111) dans le kernel-land à une adresse donnée. Disons pour l’exemple qu’à l’adresse 0xfff7 de la zone mémoire du kernel, il y a les 3 bits 100, ou 4 en décimal. C’est l’appel (1) sur le schéma. Cette valeur sera utilisée pour l’instruction suivante (2).
Évidemment, l’accès à la zone kernel est interdite, donc une exception va se lever de type SIGSEGV (Segmentation Fault), mais comme nous avons vu que les processeurs effectuaient les instructions en parallèle, les instructions suivantes peuvent être exécutées en même temps.
Ainsi, l’instruction qui suit va accéder à la 4ème section du buffer (3 sur le schéma) que nous avons préparé en amont (4 étant la valeur trouvée dans la mémoire du noyau). Cette section du buffer sera alors mise en cache par le processeur (4 sur le schéma).
Le processeur va alors se rendre compte que l’accès à la zone kernel était interdit, et va annuler l’instruction que nous venons de faire, mais la trace dans le cache n’est pas supprimée.
Le pseudo-code qui peut-être associé à cette attaque est le suivant :
var_secrete = kernel_space[0xfff7]; // var_secrete == 4 dans l'exemple
junk = buffer[var_secrete]; // Accès à l'index du buffer correspondant à la valeur récupérée
Lire l’information exfiltrée
La deuxième partie consiste à sortir cette valeur pour que l’attaquant la connaisse. En effet, pour le moment, il n’y a eu qu’une mise en cache, et il n’est pas possible de lire directement ce cache.
Pour cela, on utilise des techniques appelées cache side-channel attacks. Nous utiliserons celle appelée flush + reload pour retrouver l’information. Il en existe d’autres comme Evict+Time ou Prime+Probe que nous ne verrons pas dans cet article, mais vous pouvez aller voir cet article qui en parle si vous êtes curieux.
L’attaquant va alors simplement vider le cache, puis procéder à l’attaque, pour enfin accéder à toutes les sections du buffer qu’il avait préparé en mesurant les temps d’accès à chaque section.
// Flush
flush(buffer)
// Attaque
/* Une partie du buffer va être mise en cache, comme vu précédemment */
// Reload
int i;
for (i=0; i<8; i++)
{
printf("[%d] %d\n", i+1, access_time(buffer[i]));
}
Cela donnera une sortie comme
[1] 231
[2] 229
[3] 304
[4] 32 // <--- Temps d'accès le plus rapide, donc section mise en cache
[5] 274
[6] 299
[7] 257
[8] 311
L’information est donc maintenant connue. Comme c’est la section 4 qui est en cache, cela signifie que c’est la valeur 4 qui se trouvait à l’adresse 0xfff7 dans le kernel.
En bouclant sur les adresses réservées au noyau, nous pouvons ainsi lire le contenu de cette zone mémoire interdite, 3 bits par 3 bits, jusqu’à avoir tout son contenu.
En réalité
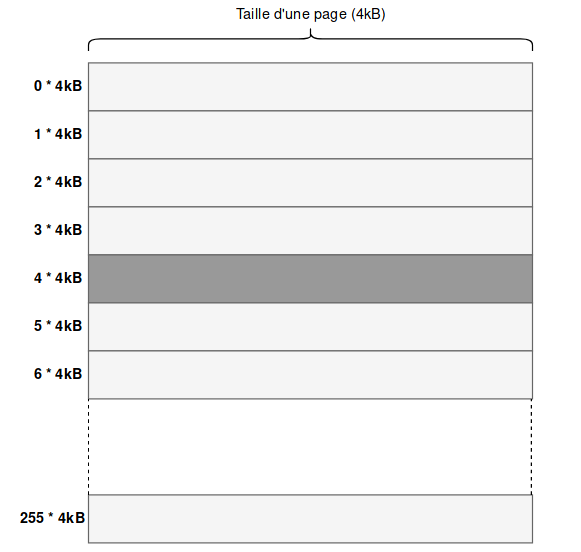
Dans notre exemple, nous avons choisi un buffer de 8 sections pour sortir les informations du noyaux 3 bits par 3 bits. Cependant, en réalité, il faut savoir que le processeur cache des cache line, qui sont des blocs de données d’une certaine taille, de l’ordre de 64 octets. Ces lignes de cache sont incluses dans des pages. Sur ma machine, une page représente 4096 octets
pixis@hackndo:~/spectre-meltdown $ getconf PAGESIZE
4096
Par ailleurs, il est plus intéressant de sortir les informations octet par octet, donc récupérer 8 bits à la fois. Chaque octet pouvant prendre 256 valeurs, il convient de créer un buffer d’une taille de 256 pages, chaque page représenter une donnée. Ainsi, les données sont toutes distantes d’au moins la taille d’une page. Voici un exemple d’initialisation de buffer avec ces paramètres
#define PAGE_SIZE 4096
#define BYTE_SIZE 256
char buffer[PAGE_SIZE*BYTE_SIZE];
Le buffer ressemblera donc à ce schéma :
Le pseudo-code que nous avions précédemment devient alors
var_secrete = kernel_space[0xfff7]; // var_secrete == 4 dans l'exemple précédant
junk = buffer[var_secrete * PAGE_SIZE]; // La page à l'index 4*4kB sera mise en cache
Le principe reste exactement le même avec ces paramètres.
Spectre
Tandis que Meltdown utilisait une faille de certains processeurs permettant de lire les adresses du noyau, l’attaque Spectre quant à elle n’utilise pas de faille, mais seulement l’optimisation de prédiction (speculative) et de cache dont nous avons parlé en début d’article pour pouvoir lire n’importe quelle valeur dans le user-land d’un processus victime.
L’idée de Spectre est d’entraîner le processeur à suivre un certain chemin lorsqu’une décision doit être prise en utilisant l’optimisation de prédiction, puis de profiter de cette prise de décision entraînée pour que le processeur prenne la branche voulue même si la condition n’est plus respectée.
Rappel
En petite digression qui sera utile pour la suite, je rappelle qu’un tableau en C est une variable qui contient l’adresse du premier élément du tableau. Donc nous avons l’égalité suivante :
char array[] = "Hello"; array == &(array[0]);Par ailleurs, je rappelle que accéder au
ièmeélément d’un tableau en écrivantarray[i], c’est strictement équivalent à écrire*(array + i). En effet, leièmeélément est à l’adresseadresse_premier_element + i, orarray = adresse_premier_elementdonc leièmeélément est à l’adressearray + i, et pour récupérer cet élément, on déréférence ceci, donnant*(array + i). D’où l’égalité suivante :char array[] = "Hello"; array[2] == *(array + 2);
Prenons l’exemple suivant
if (i < len_array1)
{
var = array2[array1[i]];
}
L’attaquant aura effectué un travail en amont qui aura habitué le processeur au fait que i soit inférieur à la longueur du tableau array1 donc que la condition soit vraie.
Ainsi, à la prochaîne exécution, le processeur s’appuyant sur le Branch Target Buffer (BTB) se dira que, comme avant, i devrait être inférieur à la taille du tableau, donc avant même que la vérification soit faite, il exécutera l’instruction suivante pour gagner du temps, à savoir var = array2[array1[i]];. Seulement cette fois, l’attaquant a décidé d’utiliser un i arbitraire, qu’il contrôle, et qui est supérieur à la taille du tableau array1.
La conséquence est que l’instruction var = array2[array1[i]] sera tout de même exécutée en prédiction, donc que array1[i] sera évalué, et vaudra par exemple 12. Une fois cette valeur trouvée, 12 dans l’exemple, l’index 12 du tableau array2 va être lu, et le contenu sera assigné à var.
Bien entendu, le processeur va ensuite se rendre compte que le i fourni n’était pas valide, donc il va annuler les instructions qu’il a pré-exécutées, donc var n’aura finalement pas de valeur. Cependant, la zone mémoire correspondant à array2[12] (avec 12 = array1[i]) aura tout de même été mise en cache, laissant une trace.
Une fois cette mise en cache effectuée, de la même manière que pour Meltdown, la technique du flush + reload est utilisée pour voir quel index de array2 a été mis en cache, permettant de découvrir la valeur secrète array[i] avec i étant trop grand normalement pour passer le test initial.
Pour généraliser et trouver la valeur à n’importe quelle adresse, et à l’aide du rappel ci-dessus, nous savons que array1[i] est équivalent à *(array1 + i) ou *(&array1[0] + i). Donc si l’attaquant veut voir ce qui se passe en mémoire à l’adresse 0xbfff1234 par exemple, un bête calcul permet de trouver le i qu’il doit fournir
// Nous voulons ceci
&(array1[i]) == 0xbfff1234;
// Or
&(array1[i]) == (&array1[0] + i) == (array1 + i);
// Donc
i = 0xbfff1234 - array1;
Une fois ce calcul en tête, l’attaquant peut extraire n’importe quel octet de la mémoire du programme en cours, dont des zones cachées contenant des mots de passe, des clés de cryptographie ou autres secrets.
Conclusion
Ces deux attaques font beaucoup parler d’elles car il n’y a pas de manière évidente et simple de les patcher donc de s’en protéger.
Concernant Meltdown, il est par exemple possible de changer totalement le mode de gestion de la mémoire en faisant en sorte que le noyau et le processus aient deux espaces d’adressage distincts, comme nous l’avions vu dans l’article le monde du kernel. Ainsi, nous pouvons passer du mode de gauche (partage de l’espace d’adressage) au mode de droite (séparation des espaces d’adressage)
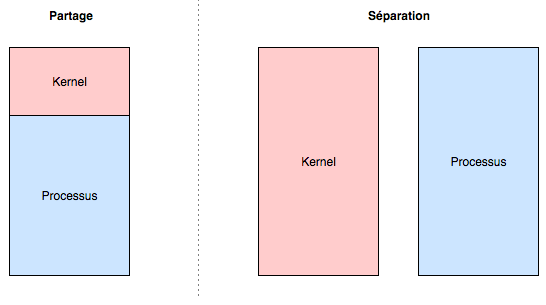
Evidemment, le processeur devra souvent changer de contexte d’exécution (user - kernel), et devra alors mettre en cache beaucoup d’informations puisqu’il devra alterner entre deux espaces d’adressage indépendants, d’où les baisses de performances dont on parle.
En ce qui concerne Spectre, il est beaucoup plus compliqué de trouver un moyen de s’en protéger. En effet, l’attaque utilise des éléments intrinsèques à l’architecture de l’ordinateur, sans utiliser de vulnérabilité, et sans accéder à des zones mémoire interdites par le matériel. Il faut donc revoir en profondeur le fonctionnement des optimisations.
Je vous invite à lire le billet de @xhark sur le sujet pour plus d’information sur les solutions et mises à jour. Il a fait un très bon travail de synthèse, je ne vais donc pas reprendre son travail.
Pour plus de détails sur les attaques, je vous mets également les whitepapers ici pour meltdown et spectre.
J’espère que cet article vous aide à y voir plus clair, n’hésitez toujours pas à commenter ou à me retrouver sur Discord pour plus d’informations, des remarques, des corrections, etc.