
Rappels d'architecture
Avant d’aller plus loin, il est nécessaire de parler rapidement de l’architecture d’un ordinateur. En effet, dans le user-land, il y a une couche d’abstraction qui permet de ne pas trop se soucier de l’architecture (quoiqu’il est nécessaire tout de même de connaitre les conventions d’appel, le nombre de bits gérés etc.), or le kernel est cette couche, donc penser être capable d’écrire des exploits corrects sans connaitre les rudiments de l’architecture d’un ordinateur n’est clairement pas imaginable.
Cet article n’a pas non plus pour vocation d’être exhaustif quant à ce sujet, nous ne parlerons donc que des éléments clés qui nous intéressent de près ou de loin pour l’exploitation de vulnérabilités au sein du kernel.
Processeur
Un CPU a un jeu d’instruction qui lui est propre (Instruction Set), lui permettant de faire des opérations, des modifications dans le flot d’exécution ou encore de modifier la mémoire. Comme les accès mémoire sont relativement lents, un CPU possède des registres. Nous avons déjà parlé des registres dans l’article sur la gestion de la mémoire. Ce sont des petites zones de mémoire au sein d’un CPU qui sont accessibles instantannément et servent à stocker des valeurs pour des calculs, pour garder des informations sur les structures en cours etc.
En ce qui concerne les jeux d’instructions, il y a deux grands familles. Les RISC (Reduced Instruction Sec Computer) et les CISC (Complex Instruction Set Computer). Les instructions des RISC ont une taille fixe et sont exécutées en un cycle d’horloge tandis que les CISC ont des instructions de tailles variables qui sont exécutées en un ou plusieurs cycles d’horloge.
Par ailleurs, les ordinateurs peuvent avoir un ou plusieurs CPU (UniProcessor UP ou Symmetric MultiProcessing SMP).
Interruptions
Lorsqu’une série d’instructions est en cours d’exécution, il est possible qu’un événement se produise et interrompe le flot d’exécution. L’origine peut être logicielle ou matérielle.
- Dans le cas des interruptions logicielles, on dit qu’elles sont synchrones puisque le même code rejoué provoquera les mêmes interruptions.
- Dans le cas des interruptions matérielles, on dit qu’elles sont asynchrones puisqu’elles peuvent survenir à tout moment (un disque qui a fini son travail, un carte réseau ayant fini de recevoir un paquet etc.).
Chaque type d’interruption a un numéro unique auquel est associée une routine à exécuter. Le CPU possède un registre spécial qui permet de savoir quelle routine correspond à quel numéro d’interruption. Ce registre pointe sur l’Interrupt Vector Table. Vous imaginez bien qu’il sera intéressant de modifier cette table…
Comme les CPU ont deux modes d’exécution, privilégié et non privilégié, comme nous l’avons dit dans l’article d’introduction sur le monde du kernel, il est possible à l’aide d’instructions fournies par le CPU dans le mode non privilégié de faire des interruptions pour exécuter du code privilégié, par exemple pour que le kernel exécute le code faillible, et ainsi exploiter la vulnérabilité.
Gestion de la mémoire
L’accès à la mémoire physique peut-être fait de manière segmentée pour certains CPU, ou linéaire (la majorité de nos jours).
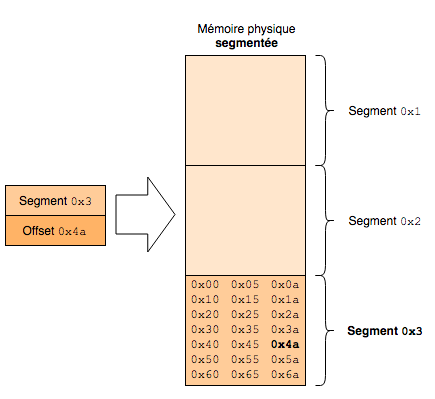
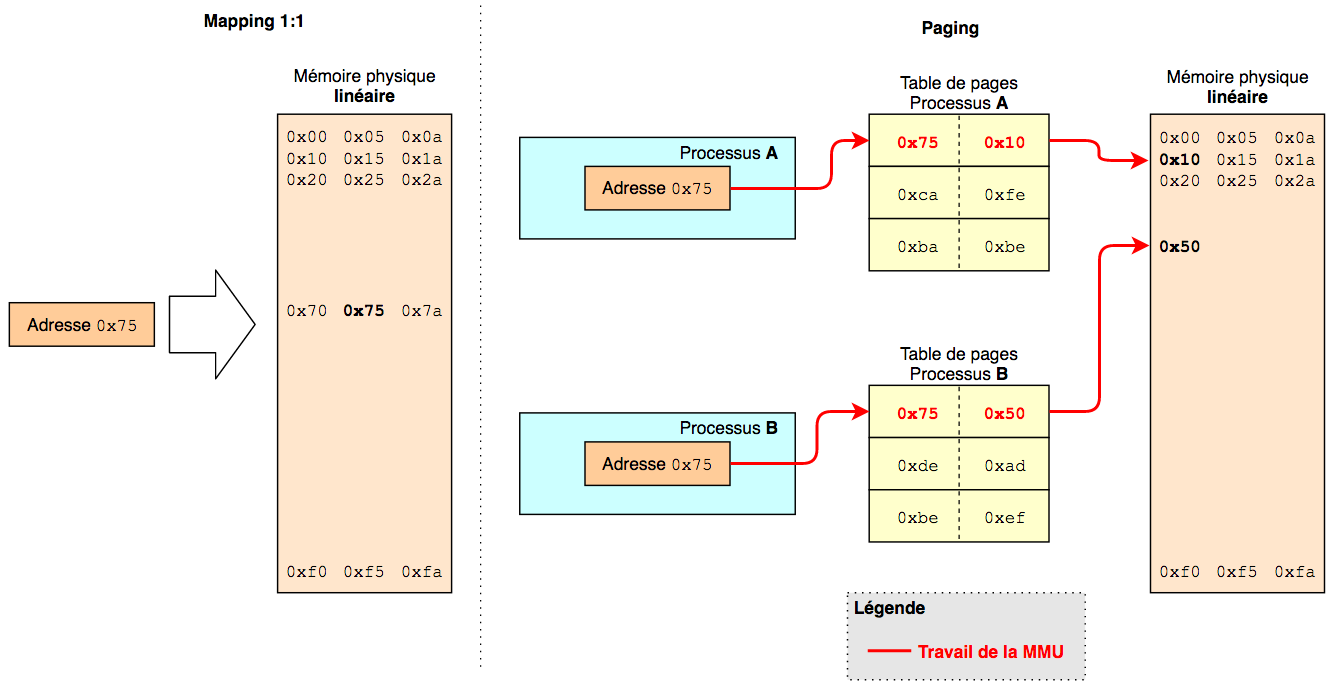
Dans un adressage segmenté, il faut donner le numéro du segment puis l’offset de la donnée dans ce segment pour la récupérer, tandis que lorsqu’il est linéaire, on peut avoir un mapping 1:1 des adresses, mais on peut également avoir de la pagination (paging) pour avoir des zones mémoires virtuelles. Dans le cas du paging, c’est la MMU (Memory Management Unit) qui s’occupe de traduire une adresse virtuelle en une adresse physique, en passant par les tables de pages.
Voici un schéma d’une mémoire physique segmentée
Puis un schéma des deux types de mémoires linéaires, l’une avec le mapping 1:1 et l’autre qui utilise le système de pagination et de mémoire virtuelle
Cependant, comme l’opération de traduction adresse virtuelle -> adresse physique est un peu coûteuse, il existe un cache appelé Translation Lookaside Buffer (TLB) qui garde en mémoire la correspondance entre adresses virtuelles et adresses physiques. C’est pratique par exemple lorsqu’on parcourt un tableau afin de ne pas devoir retrouver l’adresse du début du tableau en mémoire physique à chaque itération.
Biensûr, comme chaque processus a sa propre plage de mémoire et sa propre table de pages, il faut que la TLB soit vidée à chaque changement de processus en cours d’exécution.
Cependant, dans le cas où la mémoire est partagée (une partie pour le kernel, une partie pour le processus), même s’il y a un changment de processus, il n’est pas nécessaire de vider la TLB du kernel puisque la table de pages du kernel est répliquée pour chaque processus, et reste alors inchangée. Sa TLB est donc toujours la même.
32bits & 64bits
Nous finirons par une petite parenthèse sur quelques particularités des CPU x86-64.
- Tous les registres 32 bits (EAX, EBX, …) sont étendus à 64 bits (RAX, RBX, …)
- 8 nouveaux registres (R8-R15) sont créés
- Un bit NX (Non exécutable) est présent par défault pour les pages allouées afin de décider si oui ou non ce sont des zones mémoires exécutables
- La convention d’appel de fonction a été modifiée : Les arguments ne sont plus passés par la stack par défault, mais par des registres.
À part ces quatre grosses différences (il y en a beaucoup d’autres), la majorité des éléments que nous connaissons dans les architectures x86 restent valables.
Au programme du prochain article, nous verrons la méthodologie permettant de développer un exploit de manière propre et méhodique.
[ Prochain article en cours de rédaction ]