
Fonctionnement de la pile
La pile (dont on a parlé dans l’article sur la gestion de la mémoire a une structure LIFO (Last In, First Out).
LIFO
Cela veut dire que le dernier élément qui est placé sur la pile sera le premier élément à être dépilé. Pour mieux comprendre, on peut imaginer une pile d’assiette. Si on empile des assiettes les unes sur les autres, il faudra enlever la dernière assiette posée, puis l’avant-dernière etc. pour pouvoir récupérer la première assiette posée. C’est le même principe.
Contrairement à la pile d’assiette, la stack empile ses éléments vers le bas. Donc ce qu’on appelle le haut de la stack, c’est finalement l’adresse la plus basse de la stack. Plus on empile des valeurs dans la stack, plus les adresses diminuent. C’est déroutant, mais on s’y fait rapidement !
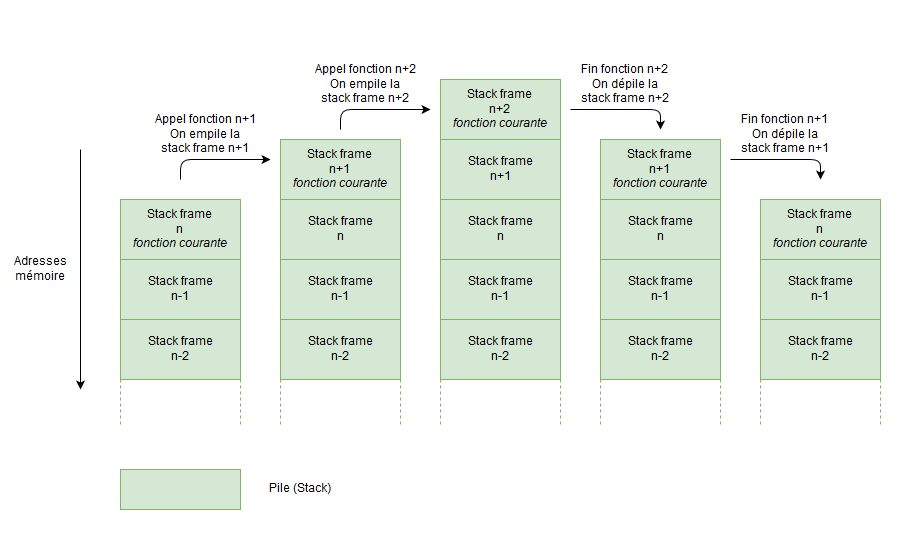
Stackframe
Cette structure LIFO est finalement extrêmement utile. En effet, lors de l’appel d’une fonction, toutes les données nécessaires pour l’exécution de la fonction, ainsi que pour le retour à l’état initial sont empilées. Une fois la fonction terminée, il faut donc retourner à la ligne suivant son appel, et ceci se fait en dépilant tout ce qui a été précédemment empilé, laissant intact le reste de la pile et les autres éventuelles stack frames. Voici un schéma qui tente de résumer mes propos :
Nous avons vu dans un article sur la gestion de la mémoire ce qu’étaient les stack frame (vous savez, ces informations stockées sur la pile lors de l’appel d’une fonction pour enregistrer le contexte d’exécution ainsi que les variables passées à la fonction). Et bien le registre ESP garde en mémoire l’adresse du haut de la pile (donc l’adresse la plus basse, puisque plus la pile grandit, plus les nouvelles adresses sont basses). Il est donc mis à jour à chaque modification de la pile (ajout d’une valeur ou suppression de la dernière valeur). Le registre EBP garde en mémoire l’adresse du début de la stack frame. Ainsi, la stack frame courante se situe entre l’adresse contenue dans EBP et l’adresse contenue dans ESP.
Voici un schéma qui illustre le rôle des registres EBP et ESP :
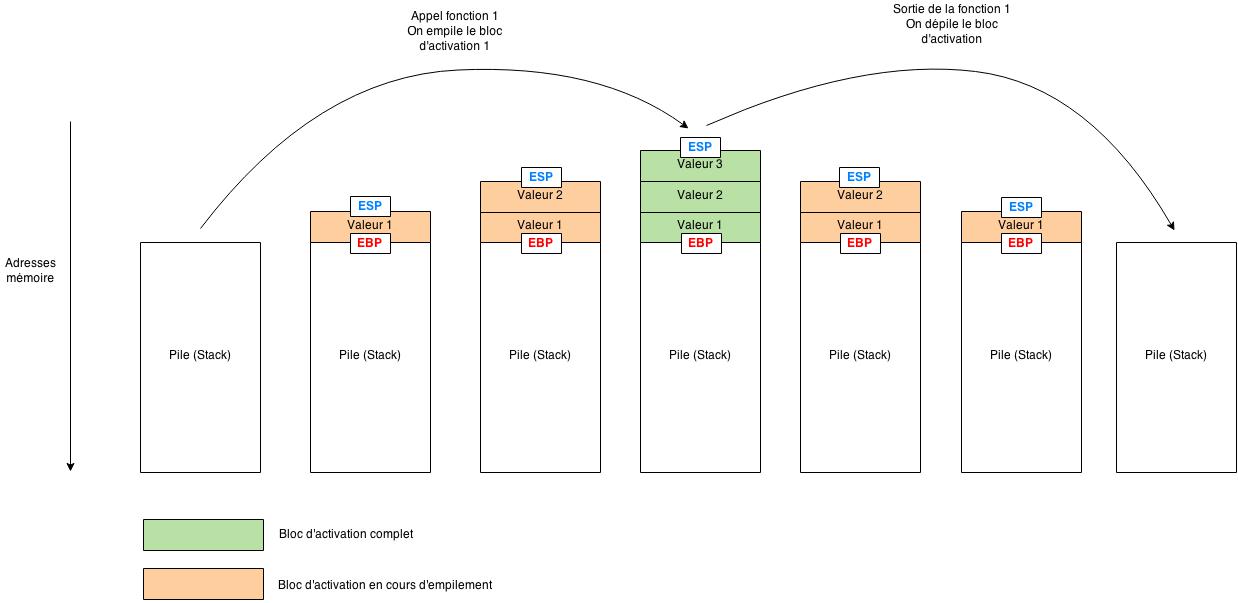
Ce que nous venons de voir est vrai tant qu’on reste dans la même stack frame. Cependant, que se passe-t-il lorsqu’il y a un appel à une nouvelle fonction ? Une fois cette nouvelle fonction terminée, comment le processeur revient-il à l’état précédent ? C’est ce que nous allons voir tout de suite.
Prologue - Épilogue
Pour être en mesure de bien comprendre la suite de cet article, des notions de base d’assembleur sont utiles. Même s’il est possible de suivre sans aucune connaissance, il est fortement conseillé de lire l’article Notions de base sur l’assembleur qui vous donnera les bases nécessaires pour une meilleure compréhension.
Considérons le programme fonction.c suivant :
#include <stdio.h>
#include <stdlib.h>
int reponse(int a, int b, int c) {
return a+b+c;
}
int main() {
int result;
result = reponse(4, 8, 42);
}
Après compilation, on désassemble la fonction main pour voir les instructions assembleur qui la compose
hackndo@becane$ gcc fonction.c -o fonction
hackndo@becane$ gdb -q fonction
Reading symbols from /home/hackndo/fonction...(no debugging symbols found)...done.
(gdb) disas main
Dump of assembler code for function main:
0x080483a5 <+0>: push ebp
0x080483a6 <+1>: mov ebp,esp
0x080483a8 <+3>: sub esp,0x1c
0x080483ab <+6>: mov DWORD PTR [esp+0x8],0x2a
0x080483b3 <+14>: mov DWORD PTR [esp+0x4],0x8
0x080483bb <+22>: mov DWORD PTR [esp],0x4
0x080483c2 <+29>: call 0x8048394
0x080483c7 <+34>: mov DWORD PTR [ebp-0x4],eax
0x080483ca <+37>: leave
0x080483cb <+38>: ret
End of assembler dump.
Si vous n’avez pas eu le temps de regarder l’article sur les notions de base d’assembleur, rappelons rapidement le rôle des commandes que nous avons utilisées.
La commande gcc (GNU Compiler Collection) est une commande sous Linux qui permettait de compiler des programmes écrits en C historiquement, mais qui maintenant permet de compiler des programmes dans différents langages (C, C++, Java…).
gdb (GNU Project Debugger) est un debugger puissant, totalement en ligne de commande. Il permet, entre autre, de désassembler un programme, de le lancer, de le mettre en pause pendant son exécution, de lire la mémoire, la modifier pendant l’exécution et j’en passe. Vous pouvez également lire l’article Introduction à GDB pour mieux comprendre son fonctionnement.
Astuce: Lorsque nous sommes dans une session gdb, il est possible de lui passer un grand nombre de commandes. Comme certaines d’entre elles peuvent avoir des noms très longs, ou peuvent être appelées extrêmement souvent, certaines abréviations peuvent être utilisées. Par exemple, la commande permettant d’avoir des informations sur les registres est info registers mais elle peut être lancée en utilisant la simple commande i r.
Pour désassembler une fonction d’un programme chargé dans gdb, nous lui passons la commande disassemble function. Ici nous souhaitons désassembler la fonction main, donc nous lançons la commande disas main, sachant que disas est un alias de disassemble, comme nous venons de l’expliquer.
On remarque différentes choses. Tout d’abord, on voit l’appel à la fonction reponse à la ligne +29 (adresse 0x080483c2) avec l’instruction call. Ensuite on remarque sur les 3 lignes précédentes qui sont l’ajout sur la pile des arguments qui seront envoyés à cette fonction : Sont placés le 3ème argument, puis le deuxième et enfin le premier.
Une fois que nous arrivons à l’instruction call, regardons l’état de la pile :
(gdb) x/8xw $esp
0xbffffc9c: 0x00000004 0x00000008 0x0000002a 0x080483eb
0xbffffcac: 0xb7fd6ff4 0x080483e0 0x00000000 0xbffffd38
Pour pouvoir lire ces informations, je vous rappelle que la pile grandit vers les adresses basses. La première ligne que nous pouvons lire commence par 0xbffffc9c suivie de 4 groupes de 4 octets. Le premier groupe est bien à l’adresse 0xbffffc9c, le groupe suivant 4 octets plus loin est donc à 0xbffffca0, ensuite le groupe est à 0xbffffca4 et enfin le dernier groupe de la première ligne est à l’adresse 0xbffffca8. On passe alors à la ligne suivante, et on avance encore une fois de 4 octets, ce qui nous donne bien l’adresse 0xbffffcac et ainsi de suite.
Le registre ESP pointe vers le “haut” de la pile, donc vers l’adresse 0xbffffc9c. Comme nous nous sommes préparés à l’appel de la fonction, le sommet de la pile (pointé par ESP) est composé des arguments qui sont passés à la fonction. On voit bien les valeurs 4, 8 et 42 (0x2a en hexadécimal).
La pile est donc dans l’état suivant :
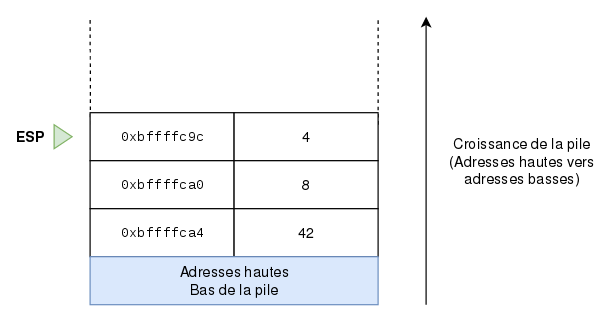
Les arguments sont donc enregistrés sur la pile. Mais une fois que le programme rentre dans la fonction, il va devoir se souvenir d’où il vient. Et pour cela, il va falloir qu’il enregistre le registre EIP (c’est le registre qui a en mémoire l’adresse de l’instruction courante). On ne voit cependant pas d’instruction PUSH EIP dans le code, tout simplement pour la raison suivante (qu’il est impératif de retenir), c’est que l’instruction call est un alias des deux instructions suivantes :
push EIP
jmp <adresse de la fonction>
Donc si nous avançons d’une instruction pour entrer dans la fonction, la valeur de EIP est poussée sur la pile, et nous obtenons :
(gdb) stepi
0x08048394 in reponse ()
(gdb) x/8x $esp
0xbffffc98: 0x080483c7 0x00000004 0x00000008 0x0000002a
0xbffffca8: 0x080483eb 0xb7fd6ff4 0x080483e0 0x00000000
On voit arriver l’adresse 0x080483c7 en haut de la pile. Vous remarquez ce que c’est ? Oui, c’est l’adresse de l’instruction qui suit le call dans le main. Au moment de rentrer dans la fonction, le processeur enregistre la prochaine instruction à suivre une fois qu’il sortira de la fonction dans laquelle il vient d’entrer.
Avec cette sauvegarde de l’EIP, nous avons donc une représentation de la pile comme suit :
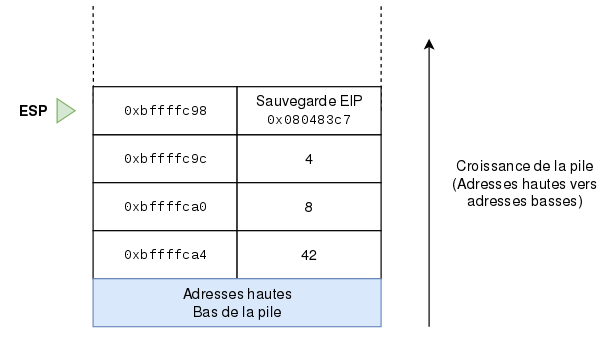
Voilà, nous avons fait le jump. Nous sommes à la première instruction de la fonction reponse()
Mais du coup cette nouvelle fonction doit avoir un espace à elle sur la stack. Sa stack frame doit être dissociée de celle de la fonction main.
En effet, rappelons que chaque fonction possède sa propre stack frame. Lorsqu’une fonction est appelée, elle va se réserver un espace sur le dessus de la pile. En dessous de cet espace se trouve la stack frame de la fonction appelante. Quand la fonction en cours sera terminée, il faudra pouvoir revenir à la fonction appelante.
Pour cela, chaque fonction possède ce qu’on appelle un prologue et un épilogue. Le prologue permet de sauvegarder les informations de la fonction appelante et de réserver l’espace sur la pile dont aura besoin la fonction, tandis que l’épilogue permet de restituer ces informations sauvegardées pour que la fonction appelante puisse reprendre son cours d’exécution comme si rien ne s’était passé.
Prenons le code de la fonction reponse pour voir en détail comment cela fonctionne.
(gdb) disas reponse
Dump of assembler code for function reponse:
0x08048394 <+0>: push ebp
0x08048395 <+1>: mov ebp,esp
0x08048397 <+3>: mov eax,DWORD PTR [ebp+0xc]
0x0804839a <+6>: mov edx,DWORD PTR [ebp+0x8]
0x0804839d <+9>: lea eax,[edx+eax*1]
0x080483a0 <+12>: add eax,DWORD PTR [ebp+0x10]
0x080483a3 <+15>: pop ebp
0x080483a4 <+16>: ret
End of assembler dump.
Le prologue de cette fonction est constitué des lignes +0 et +1.
On voit dans l’ordre que EBP est poussé sur la pile avec PUSH EBP, permettant de sauvegarder le registre EBP sur la pile, registre qui pointait vers le début de la stack frame précédente. A la ligne +1, la valeur de ESP est copiée dans EBP. A ce moment là, EBP et ESP pointent vers la même case mémoire. C’est normal, nous venons de commencer la stack frame de la fonction appelée, et elle n’a encore rien mis dessus. Donc le début et la fin sont confondus !
D’ailleurs, si on regarde l’évolution des registres EBP et ESP ainsi que de la pile lors de l’exécution des premières instructions de la fonction reponse() on obtient ceci :
(gdb) disas reponse
Dump of assembler code for function reponse:
=> 0x08048394 <+0>: push ebp
0x08048395 <+1>: mov ebp,esp
0x08048397 <+3>: mov eax,DWORD PTR [ebp+0xc]
0x0804839a <+6>: mov edx,DWORD PTR [ebp+0x8]
0x0804839d <+9>: lea eax,[edx+eax*1]
0x080483a0 <+12>: add eax,DWORD PTR [ebp+0x10]
0x080483a3 <+15>: pop ebp
0x080483a4 <+16>: ret
End of assembler dump.
(gdb) i r $ebp $esp
ebp 0xbffffcb8 0xbffffcb8
esp 0xbffffc98 0xbffffc98
(gdb) continue
Continuing.
Breakpoint 1, 0x08048397 in reponse ()
(gdb) disas reponse
Dump of assembler code for function reponse:
0x08048394 <+0>: push ebp
0x08048395 <+1>: mov ebp,esp
=> 0x08048397 <+3>: mov eax,DWORD PTR [ebp+0xc]
0x0804839a <+6>: mov edx,DWORD PTR [ebp+0x8]
0x0804839d <+9>: lea eax,[edx+eax*1]
0x080483a0 <+12>: add eax,DWORD PTR [ebp+0x10]
0x080483a3 <+15>: pop ebp
0x080483a4 <+16>: ret
End of assembler dump.
(gdb) x/8xw $esp
0xbffffc94: 0xbffffcb8 0x080483c7 0x00000004 0x00000008
0xbffffca4: 0x0000002a 0x080483eb 0xb7fd6ff4 0x080483e0
(gdb) i r $ebp $esp
ebp 0xbffffc94 0xbffffc94
esp 0xbffffc94 0xbffffc94
Reprenons ce code pas à pas : Nous sommes au début des instructions de la fonction, près à exécuter le push ebp. On voit que EBP contient l’adresse 0xbffffcb8 et esp contient 0xbffffc98. On retrouve bien le ESP qu’on avait représenté sur le dernier schéma. Ensuite, nous avançons de deux instructions. On regarde alors EBP et ESP. Ils sont bien égaux, comme prévus. On a poussé l’ancienne valeur de EBP sur la pile, ce qui a décalé de le haut de la pile de 4 octets. Le haut de la pile vaut donc 0xbffffc98 - 4 donc 0xbffffc94. Ensuite, on affecte ESP à EBP. ESP valant maintenant 0xbffffc94, EBP prend la même valeur, comme le montre la dernière commande de cette séquence. Voici un dernier schéma qui représente l’état actuel de la pile :
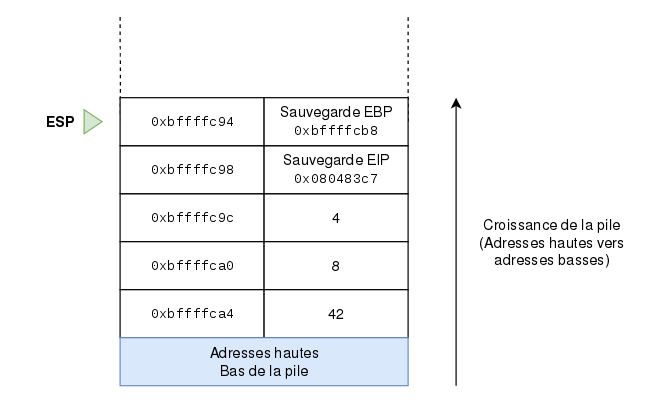
Voilà pour l’explication de ces lignes dans gdb. Ensuite nous avons quelques instructions qui permettent d’effectuer le calcul demandé, puis nous arrivons aux deux dernières lignes, qui sont pop ebp et ret.
La première va permettre de replacer le pointeur EBP sur le début de la stack frame de la fonction appelante, tandis que le deuxième permet de POP EIP (donc renvoyer la sauvegarde de EIP dans le registre EIP) pour reprendre le cours de l’instruction qui était à la suite de l’appel de fonction. Cette routine peut se résumer très sommairement au schéma suivant :
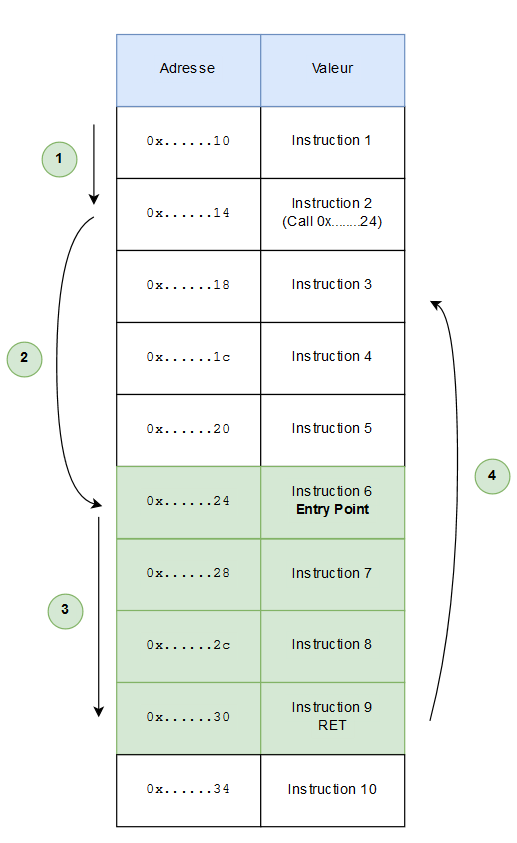
Le programme est lu instruction par instruction (1). Lors d’un call (2), on empile l’instruction en cours (EIP est pushée sur la pile), puis on saute à l’adresse donnée par le call. Ici, les instructions de la fonction sont exécutées les unes à la suite des autres jusqu’au RET (3) qui va récupérer la valeur de EIP enregistrée précédemment, afin de revenir à là où le programme en était (4), sans perdre le fil !
Magique, non ?
Avec cette compréhension un peu plus détaillée, vous êtes à même de comprendre le concept du buffer overflow, expliqué dans l’article Buffer Overflow