

Les failles kernel
Avec l’article d’introduction sur le monde du kernel, nous avons tous les éléments théoriques généraux qui permettent de comprendre pourquoi il est intéressant de trouver des failles dans le kernel.
Nous allons donc voir maintenant quelles sont ces failles. Non, nous n’allons pas encore mettre les mains dans le cambouis. Mais ce monde est tellement vaste qu’il est nécessaire d’avoir une vue globale avant de plonger la tête la première. Vous allez voir, ça reste quand même intéressant.
Par ailleurs, si vous avez des connaissances concernant les vulnérabilités existantes dans le User-Land, vous verrez qu’il y a beaucoup de ressemblances.
Problèmes de pointeurs
Un pointeur contient une adresse, et lorsqu’on veut récupérer ce qui se trouve à cette adresse, on déréférence le pointeur. Malheureusement (?) il existe de nombreux cas où les pointeurs ne pointent pas ou plus vers l’adresse voulue par le programmeur.
Par exemple, un pointeur statique est initialisé à NULL en C, NULL étant égal à 0x00. Si jamais aucune autre valeur n’est associée au pointeur, et qu’il est déréférencé, alors ça créera un problème car le processus ou le kernel essaiera d’accéder à l’adresse mémoire 0x00 mais il y a rarement quelquechose de mappé à cette endroit. Rarement… Mais comme c’est dans le User-Land, nous pouvons mapper cette zone mémoire et y écrire ce que nous voulons.
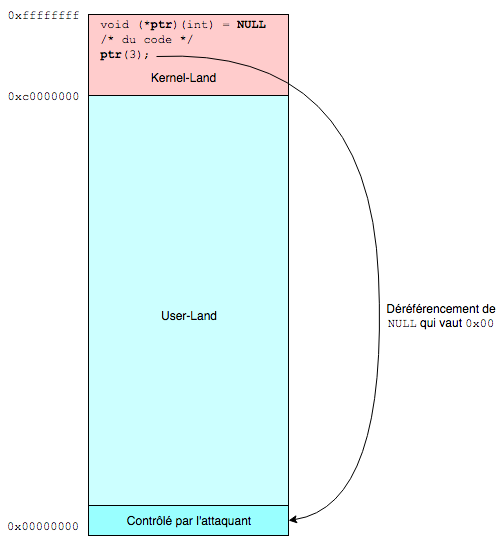
De la même manière, si jamais la valeur d’un pointeur est écrasée, par exemple suite à un overflow, alors lors du déréférencement, au mieux si la zone mémoire est mappée, la valeur récupérée ne sera pas celle attendue et au pire il y aura un panic.
Il est donc très intéressant pour l’attaquant de voir comment tirer partie de ces problèmes de déréférencement avec les pointeurs NULL ou les pointeurs corrompus, dès lors qu’ils ne sont pas vérifiés avant d’être utilisés.
Corruption mémoire
La mémoire peut être corrompue à deux niveaux. Dans la stack, associée à chaque thread quand il y a du code du kernel qui est exécuté (par exemple avec les syscalls), et dans la heap lorsque le code du kernel a besoin d’allouer de l’espace.
Kernel Stack
Lorsqu’un processus est en cours d’exécution, il a deux stacks : une dans le user-land, et une dans le kernel-land.
Les deux fonctionnenent de manière relativement similaires, cependant la stack dans le kernel-land a quelques particularités : Sa taille est limitée, et toutes les stack kernel des processus partagent la même plage de mémoire, puisque la mémoire virtuelle du kernel est répliquée pour tous les processus. Ces stacks commencent et s’étendent à différents offset du Kernel-Land.
Magré ces différences, les vulnérabilités que nous connaissons pour la stack dans le user-land s’appliquent très bien pour le kernel-land (buffer overflows et variantes).
Kernel Heap
Le kernel a besoin de mémoire pour stocker différents objets. Par exemple, si un processus ouvre un fichier, le kernel devra enregistrer quelque part les informations nécessaires pour garder la trace de cette ouverture de fichier. Pour cela, un alloueur de mémoire interne au kernel, optimisé pour lui, communique avec l’alloueur de mémoire situé au niveau matériel, et demande des pages mémoires qu’il divise en morceaux, chunks, pour stocker les objets.
Si une page est remplie, une nouvelle page est demandée, et les infos de chaque page sont enregistrées, parfois au début ou à la fin de la page.
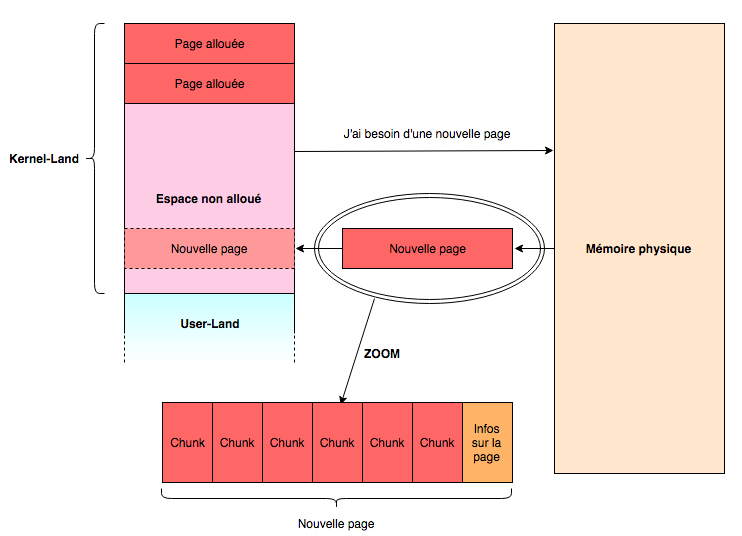
Par ailleurs, sans rentrer dans les détails, on peut parfois prédire assez précisément l’ordre des chunks qui seront utilisés, donc on peut organiser l’ordre des objets que l’on utilise dans une page. C’est un vecteur d’attaque car avec des techniques d’overflow il est possible d’écrire sur des objets que l’on choisi, ou encore d’écrire sur les infos de la page mémoire utilisée.
Problèmes d’entiers
Différents problèmes existent avec les entiers. Les plus communs sont les overflows d’entiers et les problèmes de conversion de signes.
Les overflow d’entiers, c’est lorsqu’on essaie de faire rentrer un entier trop grand dans une variable. Si l’entier n’est pas signé (donc seulement des valeurs positives) alors le comportement est souvent de supprimer les bits qui “dépassent”, et si l’entier est signé, il y a dans la plupart des cas une inversion de signe.
Prenons cet exemple pour une architecture 32bits.
/* count est un entier */
size_t ssize;
if (count <= 0) { // [1]
return (EINVAL);
}
ssize = sizeof(myStructure_t) * count; // [2]
myList = kmalloc(ssize, __GFP_WAIT); // [3]
Dans cet exemple, count va être multiplié par la taille de la structure myStructure_t qu’on considère de 4 octets. Si jamais count vaut plus que 0x3FFFFFFF, la vérification en [1] est toujours sautée parce que count est spérieur à zéro, mais suite à la multiplication [2], ssize va avoir une valeur trop grande pour rentrer dans un size_t qui ici est une valeur pouvant contenir 32 bits. En effet 0x40000000 * 4 = 0x100000000, valeur de 35 bits. Le résultat est que le bit de poids fort en trop est supprimé, donc la valeur de ssize sera 0. Ainsi, myList aura une taille plus petite que prévue suite à [3]. Il suffit alors que plus loin dans le code, on essaie d’accéder ou d’écrire à un emplacement mémoire attendu de myList pour créer un overflow.
On rencontre également des soucis avec les entiers lors de conversion de signes. Lorsqu’un entier est considéré comme signé à un endroit, et non signé à un autre, il peut alors prendre deux valeurs totalement différentes, ce qui est rarement voulu par le programmeur, et exploitable par … nous !
signed int myLen;
// [...]
/* Nous contrôlons myLen */
// [...]
if (myLen < 10) // [1]
memcpy(buff, ptr, myLen) // [2]
Comme nous contrôlons myLen nous pouvons lui donner une valeur négative qui passera la vérification [1]. Cependant, le prototype de memcpy est
void* memcpy( void *dest, const void *src, size_t count );
donc on voit que count est de type size_t qui est en fait un entier non signé. Ainsi, notre myLen va être converti en un entier non signé qui peut potentiellement avoir une taille bien supérieure à 10 et ainsi provoquer un overflow en [2].
Race conditions
Une race condition peut arriver lorsque au moins deux acteurs entrent en concurrence, et que le résultat des opérations diffère selon l’acteur qui a agit avant l’autre. Ça se produit lorsque les deux acteurs travaillent en même temps, quand plusieurs CPU tournent par exemple, ou lorsqu’ils s’entrecroisent s’il n’y a qu’un CPU et que ce CPU alterne entre les deux tâches pour qu’elles s’exécutent avec un pseudo-parallèlisme.
Ainsi, si nous nous intercalons entre des instructions du kernel, nous pouvons trouver des vecteurs d’exploitation.
struct stat st;
if (stat(filename, &st) == 0)
size = st.st_size;
// [...]
buff = kmalloc(2048, __GFP_WAIT);
if (size < 2048) {
// ---------------------- [1]
while (ret > 0)
ret = vfs_read(file, buff, size, &offset);
}
Dans cet exemple, un buffer buff de 2048 octets est préparé pour recevoir le contenu d’un fichier. On vérifie que la taille du fichier est inférieure à 2048 octets, et si c’est le cas, on copie sont contenu dans buff. Mais si modifions le contenu du fichier entre la vérification et la copie en [1], il est alors possible de créer un fichier plus grand que 2048 octets et ainsi provoquer un buffer overflow.
Autres bugs
Il existe encore plein d’autres bugs exploitables. Un dernier exemple, les compteurs de références. En effet, il y a plein de choses qui sont partagées entre les processus. Le kernel ne va allouer de la mémoire pour un objet qu’une seule fois, et il partagera cette mémoire aux processus qui en ont besoin. Il garde en mémoire le nombre de processus qui l’utilisent, et lorsque ce nombre tombe à zéro, alors l’objet peut être libéré.
Mais il arrive parfois que des morceaux de codes oublient de notifier le kernel qu’il n’ont plus besoin de l’objet. Dans ce cas, l’appel à ce morceau de code (qui alloue sans libérer) en boucle va faire augmenter le compteur de références du kernel, jusqu’à un integer overflow, qui peut ensuite être potentiellement exploité.
Voilà, nous avons fait un passage sur les grands bugs rencontrés qui peuvent conduire à des exploitations du kernel. Mais alors, comment les exploiter ? Pour cela, nous avons besoin de quelques rappels nécessaires sur l’architecture d’un ordinateur